はじめに
前回は会社情報の調査を自動化する方法をご紹介致しましたが、
今回は添付ファイルをOCRして内容をkintoneレコードに転機する方法をご紹介致します。
紙や画像のまま流入してくる書類は、検索できない・転記作業が大変・ミスが出やすいの三重苦です。
本記事では、kintoneの添付ファイルにアップされたPDF/画像をn8nでOCR→生成AIで整形→レコードへ自動記入する流れを紹介します。
具体的なフローは後述の図とステップをベースに、そのまま再現できる形でまとめました。
全体アーキテクチャ
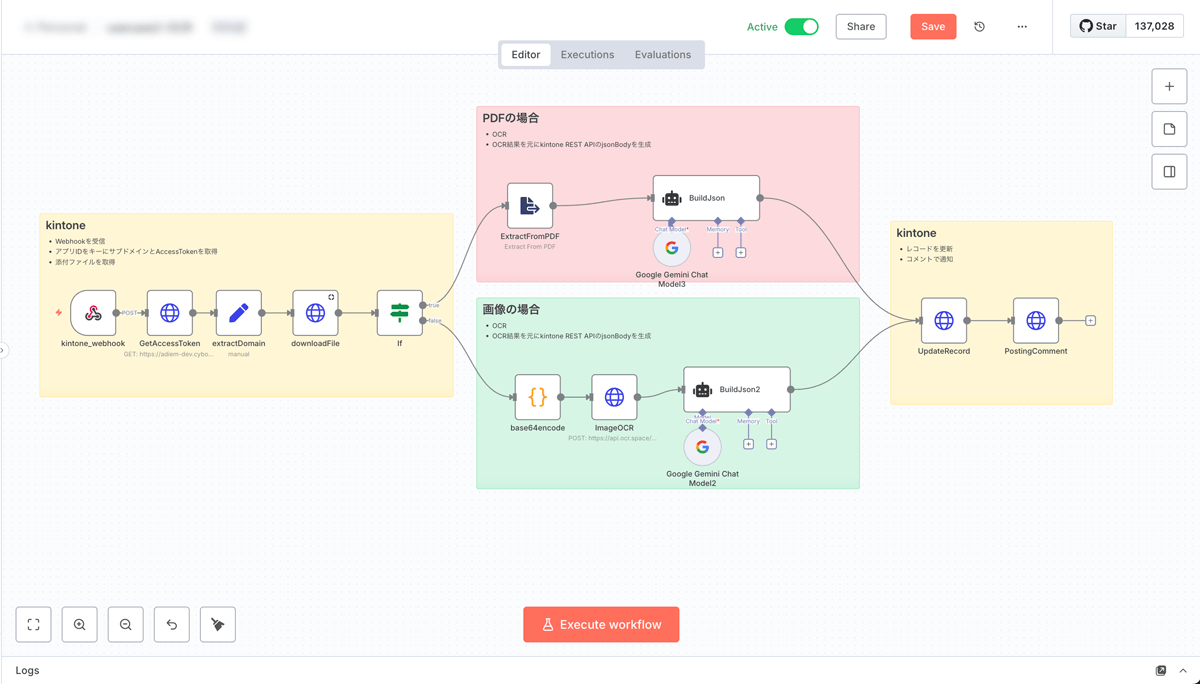
これで解決できること
- 転記の手間をゼロに:添付→自動で主要項目が埋まる
- ミス削減:AIで表記ゆれ(全角/半角・単位)を整理
- ファイルの検索性:文字列での検索が可能に
使うツールと役割
- kintone:添付ファイルの格納場所と、データのハブ
- n8n:Webhookで起動し、取得・分岐・OCR・AI整形・更新・通知をつなぐ配線係
- 生成AI:OCR結果を要約/抽出/正規化し、kintone更新用のJSONに整形
実装
1) データの受け取りと認証情報の取得
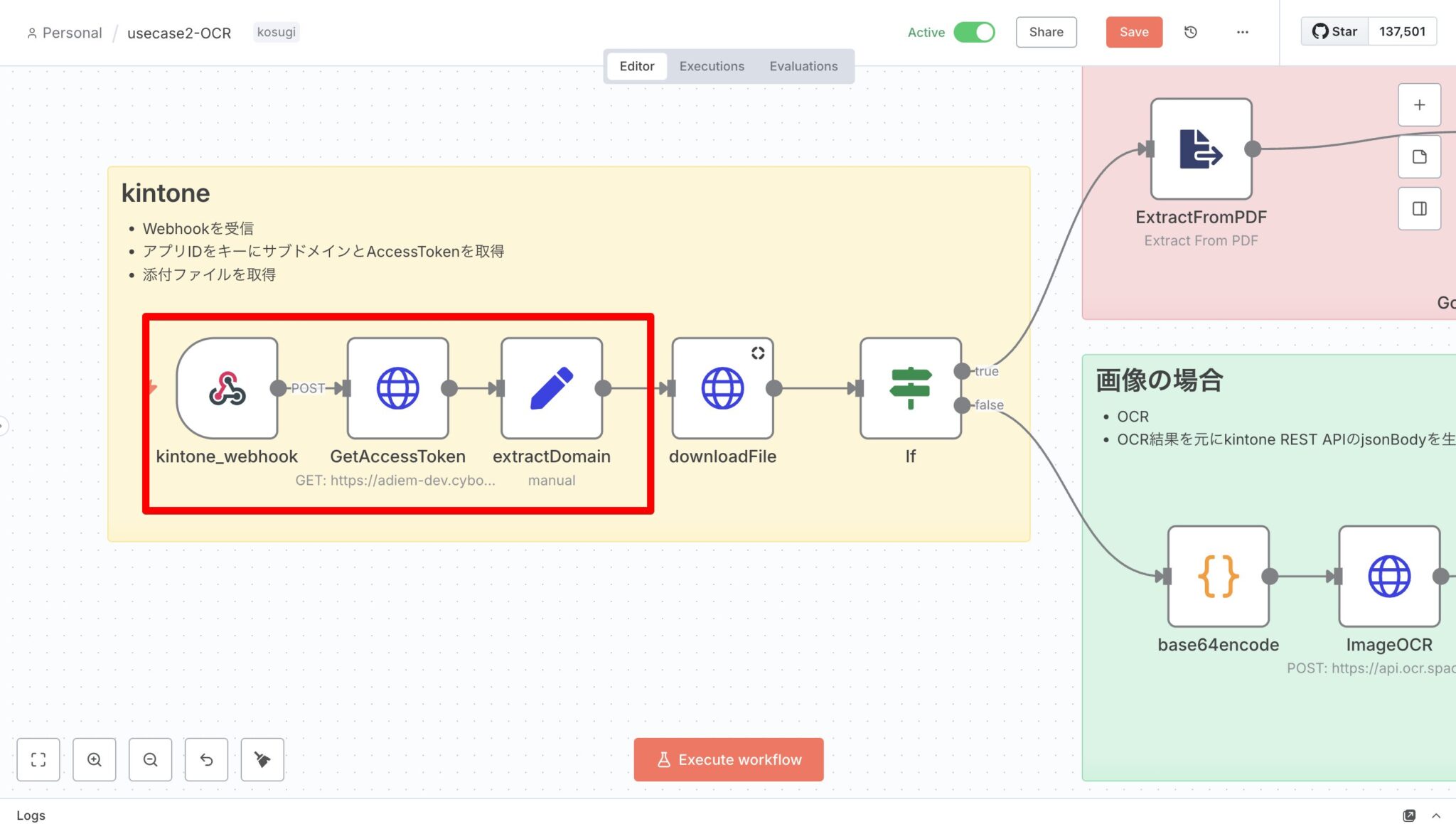
- Webhook:kintoneのレコード追加/更新をトリガーに、POSTでレコード情報を取得。
- GetAccessToken(HTTP Request):APIトークン管理用アプリからアプリIDをキーにトークンを取得。
※この管理方法は、あくまでもサンプルです。 - extractDomain(Set):アプリURLからサブドメインを抽出(正規表現)。
2) 添付の取得と分岐
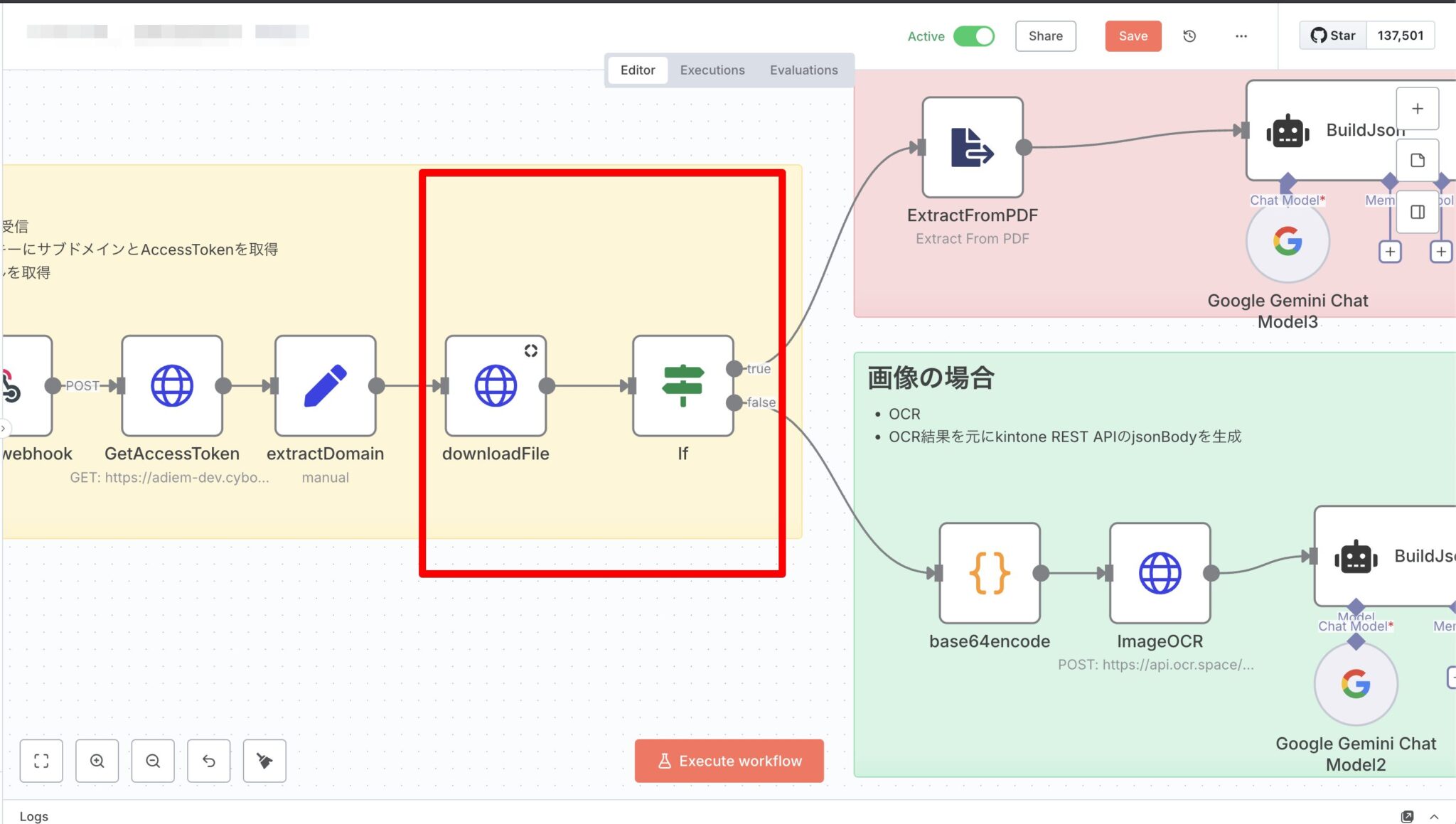
- downloadFile(HTTP Request):(extractDomainで抽出したドメイン)
/k/v1/file.jsonにfileKeyを渡してバイナリ取得。 - If:コンテンツタイプに
pdfが含まれるかでPDF/画像の分岐。
3) OCR / テキスト抽出
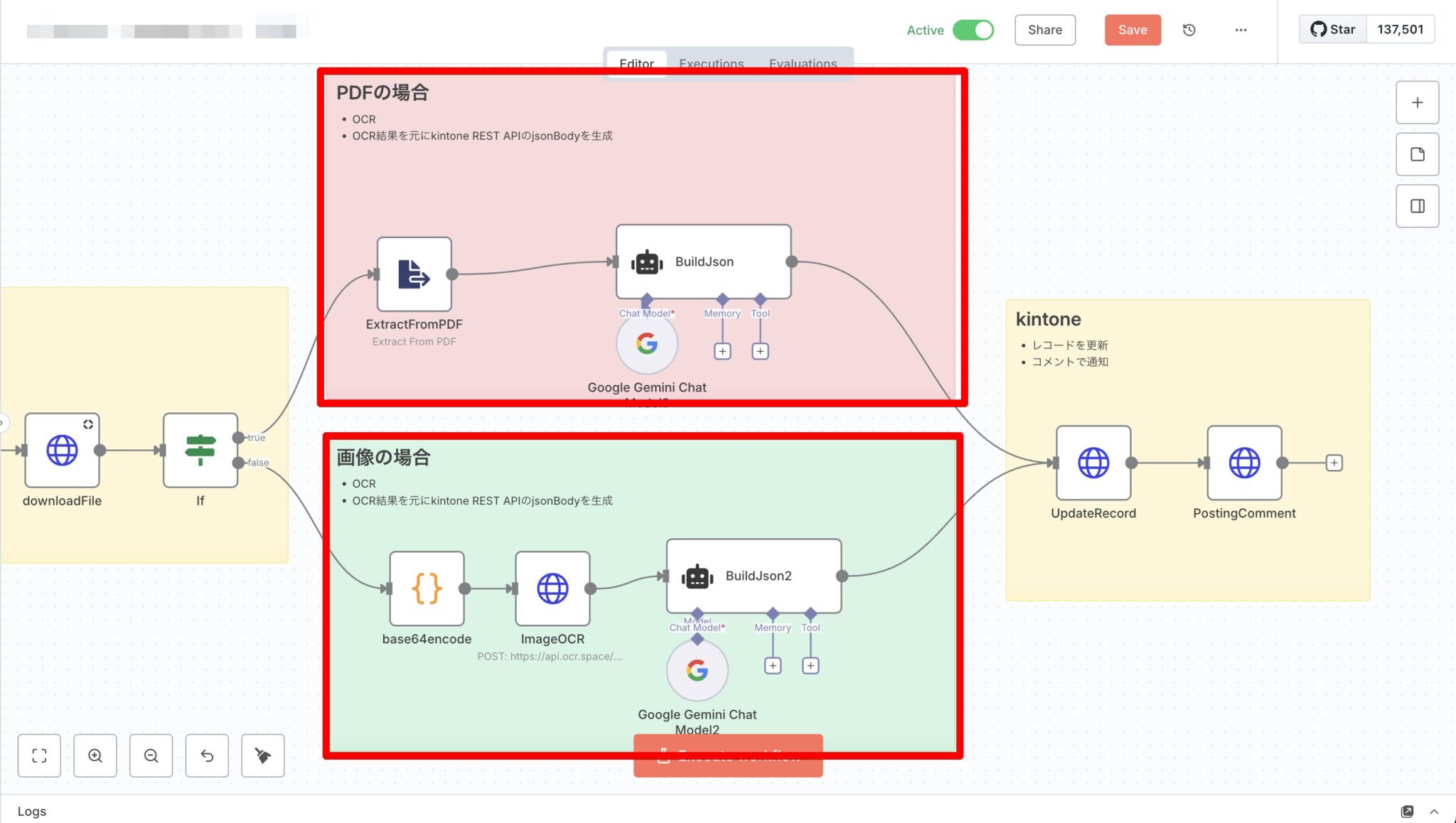
- ExtractFromPDF(PDFのとき):PDFからテキスト抽出。
- base64encode → ImageOCR(HTTP Request)(画像のとき):
base64imageをOCR APIに送信し結果をリクエスト。 - BuildJson / BuildJson2(Agent):
- 入力:PDF抽出テキスト or OCR結果
- 出力:kintoneの更新JSON(対象アプリ/レコードID/フィールドコードに合わせた形式)
- ルール:会社名は正式名称、数量は半角数値…など、バリデーション指示をプロンプトで徹底。
4) 書き戻しと通知
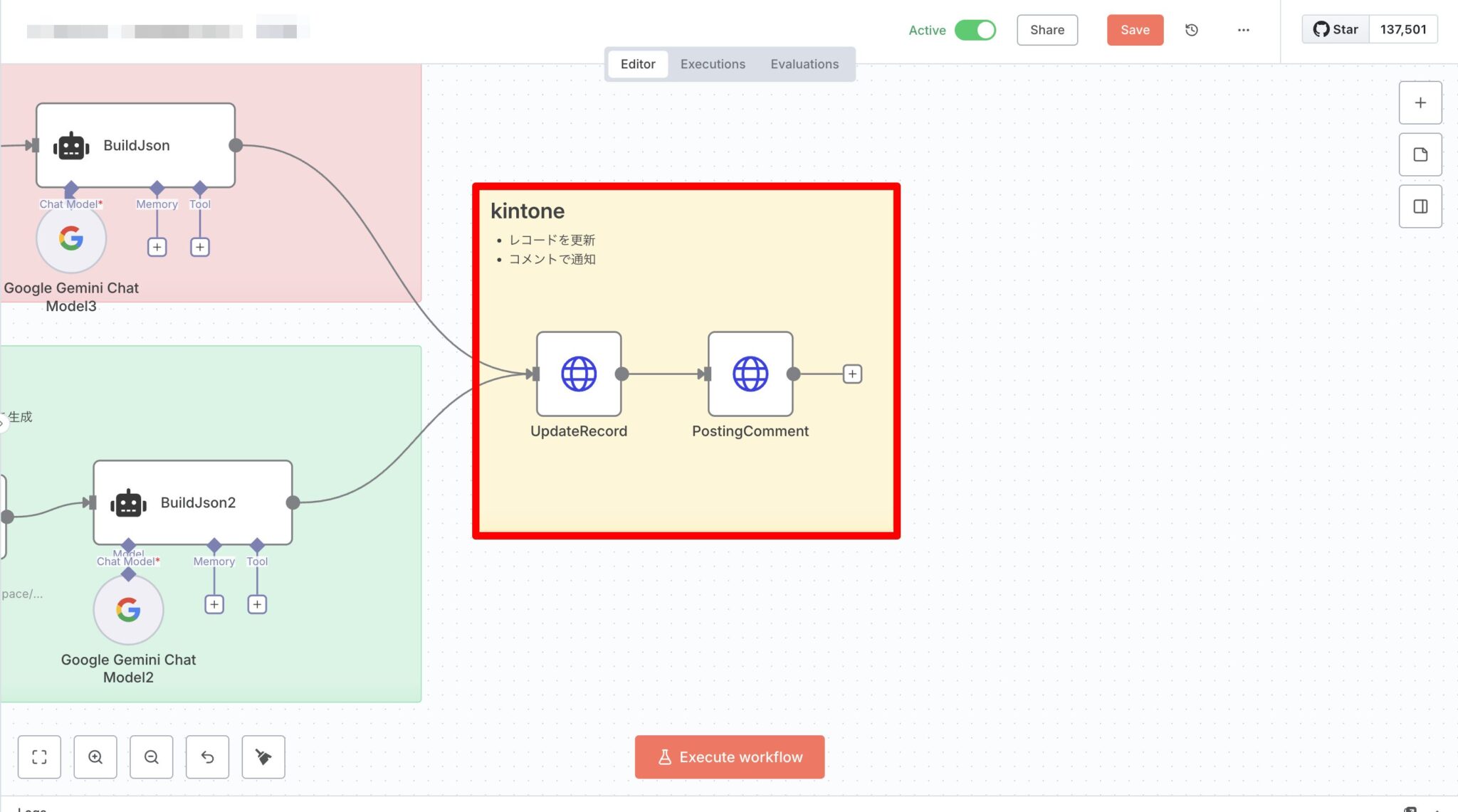
- UpdateRecord(HTTP Request):(kintoneドメイン)
/k/v1/record.jsonでレコード更新。 - PostingComment(HTTP Request):(kintoneドメイン)
/k/v1/record/comment.jsonで「OCR完了」をコメント通知(更新者メンション)。
セキュリティと運用の勘所
- トークンはCredentialsで暗号化保管:n8nの環境変数/資格情報を使い、平文埋め込みは避ける。
- ログ:n8nの実行IDをkintoneに書き残し、再実行しやすくする。
品質を上げる小ワザ
- 入力を短く:長文PDFはページ単位でOCR→AIに渡すと精度とコストが安定。
- 正規化:全角/半角・単位・日付の表記ゆれをプロンプトで明示。
- 例外フロー:低信頼(信頼度スコア)や空データ時は「保留」に振り分け、人が確認。
よくある質問(FAQ)
Q. PDFと画像で精度は変わる?
A. PDFはテキスト抽出が効く場合があり高精度になりやすいです。スキャンPDFや画像はOCRを通すため、画質・傾き・余白の影響を受けます。
Q. 生成AIは必須?
A. OCR結果は生テキストのため、フィールドに合わせた整形(正規化・抽出・構造化)にLLMを使うと実運用が楽です。
Q. 個人情報は扱える?
A. 扱う場合は、匿名化やマスキング・外部送信の制限をポリシー化し、機密はAIへ渡さない設計を推奨します。
まとめ
- 添付→OCR→AI整形→レコード更新までをn8nで一筆書きにすると、日々の転記がなくなります。
- APIトークンの一元管理と出典の保持で、保守と監査のコストを下げられます。
- まずは対象アプリを限定し、失敗時の扱いと通知を決めるところから小さくスタートしましょう。
![]()
最後に
株式会社アディエムでは、kintone × 生成AIで日々の業務改善に取り組んでいます。
今回ご紹介したようなワークフローの他にも、お客様の業務に合った改善をご提案させて頂きます。
無料相談も行なっておりますので、お気軽にお問い合わせ頂ければ幸いです。
関連記事

2026-03-04
Google Analytics × n8nで、Webサイトのアクセスデータをkintoneに自動表示してみた
Google Analytics 4(GA4)は、Webサイトの訪問者数やページ閲覧数を自動記録するGoogleのツールです。GA4のアクセスデータをkintoneに自動連携し、ダッシュボードとして表示する方法を解説します。 この記事は、kintone管理者・…
2026-02-23
n8nの「セルフホスティング」で安全にkintoneと連携!料金や導入手順を紹介
「業務を自動化したいけど、機密データをクラウドに上げるのは怖い」 製造業の現場では、こうした声をよく耳にします。 実は、n8nのセルフホスティングを使えば、機密データを社外に出さず、月額約3,000円で業務自動化を実現できます。 この記事では「セルフホスティン…
2026-02-19
kintone「アプリ設定レビューAI」の使い方|運用前のAIチェックで手戻りを防ぐ
kintoneでアプリを作成・管理している方へ。実際の現場でアプリを使い始めた後に「使いにくい」と言われた経験はありませんか? kintoneの「アプリ設定レビューAI」を活用すれば、運用開始前に問題点を発見し、手戻りを防げます。 この記事では、アプリ設定レビ…


